This post is for vRealize Automation / vRealize Orchestrator 8 administrators with no or little experience in Codestream. It will show one use case where vRealize Codestream could come in handy to automate things in form of a pipeline using vRealize Orchestrator workflows.
Introduction
As a vRealize Automation 8 user you probably clicked on the “Codestream” tile wondering what this is all about. If you dug a littler deeper, the offcial VMware Docs will introduce it as this:
“VMware Code Stream™ is a continuous integration and continuous delivery (CICD) tool. By creating pipelines that model the software release process in your DevOps lifecycle, you build the code infrastructure that delivers your software rapidly and continuously.”
If you know for example GitLab or GitHub CI/CD pipelines, this is VMware’s implementation of it. As a part of the vRealize suite it will offer some benefits in terms of integration with other suite products such as vRA or vRO. Now you might not be a developer yourself and you’re not really into pipelines, but there might be situations were you could make really good use of CodeStream. In this example I’m going to show you on how I approached this.
Use Case:
As a vRA admin you probably have blueprints that make use of image mappings or a direct imageRef. Depending on the structure of your company you either update these images by yourself or there is probably another team taking care of this. The situation is most likely:
- You build a new verson of your image
- You test the image
- You release the image to production if all tests were successful.
Depending on your OS patch release cycle this can consume a considerable amount of time if you do this manually. We could make life a lot easier if we do this in an automated fashion. This will also give us the benefit of keeping things trackable and reproducable.
Current Situation: I will describe this for one specific template. There are of course multiple templates of which we have to take care of:
- A VM that gets PXE booted to receive it’s latest OS build from a system like ansible for example.
- VM gets cloned to a template with a “-passive” suffix
- “Passive” template gets deployed as VM
- VM gets tested according to a playbook specified for this OS.
- If ok, the deployment gets deleted and the passive template will become the new active template in vRA. The old active template will be kept in case one needs to revert back to it.
Desired Situation:
Above steps should be automated as a pipeline in Codestream using vRO Workflows which get triggered from there. The pipeline itself should be triggered with its input values via a service broker item available to the user carrying out the template updates.
A few questions that might pop up could be:
- What are the vRO workflows we need to code to achieve all actions mentioned above ?
- How do I string these together as a pipeline in Codestream ?
- How does Codestream send input parameters to a workflow and how are we going to get some output back to Codestream ?
- How do we make the Codestream pipeline available in vRA’s Service Broker ?
The next sections will break down on how you could approach this by putting together all the pieces needed. We fast forward and take a look at the finished pipeline first so you can always reference back to it when we dive into vRO.
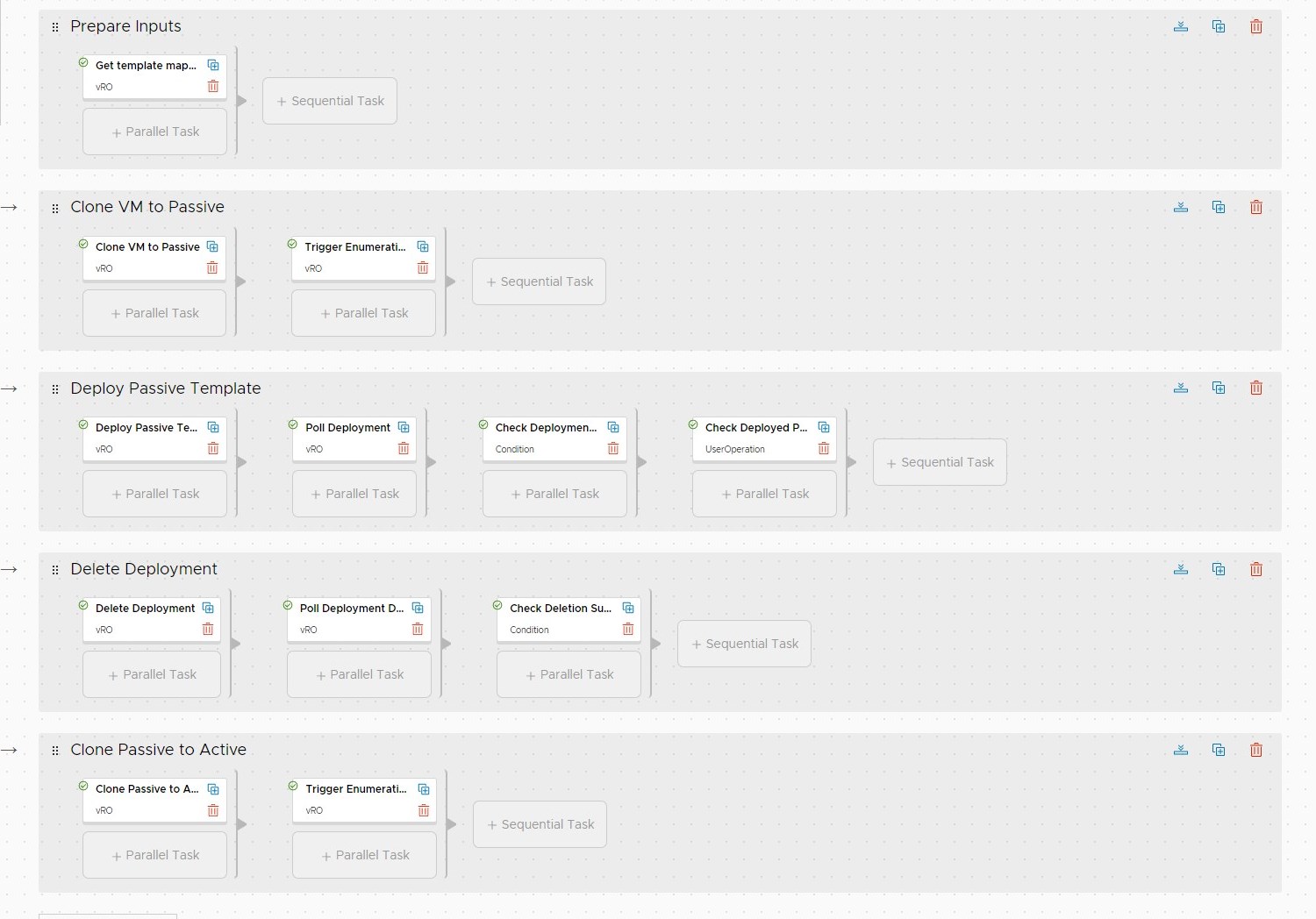
Codestream Pipeline Overview
Below is a picture of the actual codestream pipeline we are a going to build. It is basicly divided into the steps described in “Current Situation” and should be almost self explanatory by the descriptions. As you can see almost all of the elements trigger a vRO Workflow. This is where the tight integration between the products come in to play: Paramtaer binding and authentication is quite easy.
Orchestrator Workflows
Before we start getting into vRO code we should look at the current situation again and break all those tasks down in a more generic way. Like this you might even be able to use those workflows again in a different scenario…
Disclaimer: I will not cover everything in full detail when it comes to vRO as this would be way too much to cover in a post. This is more about getting an overview on how to build this.
So at a first glance, what do we actually need :
- vCenter: Clone a VM to a template / Clone a template to a template / Delete a template / Rename a template
- vRA: Make vRA aware of new templates (Image enumeration)
- vRA: Request a deployment
- vRA: Delete a deployment
Thinking some more I quickly discovered that I also need some kind of mapping table to hold together the following topics:

This will tie together all the values we need as inputs for the steps we are trying to achieve. This looks like a good opportunity to make use of vRO’s own configuration elements:
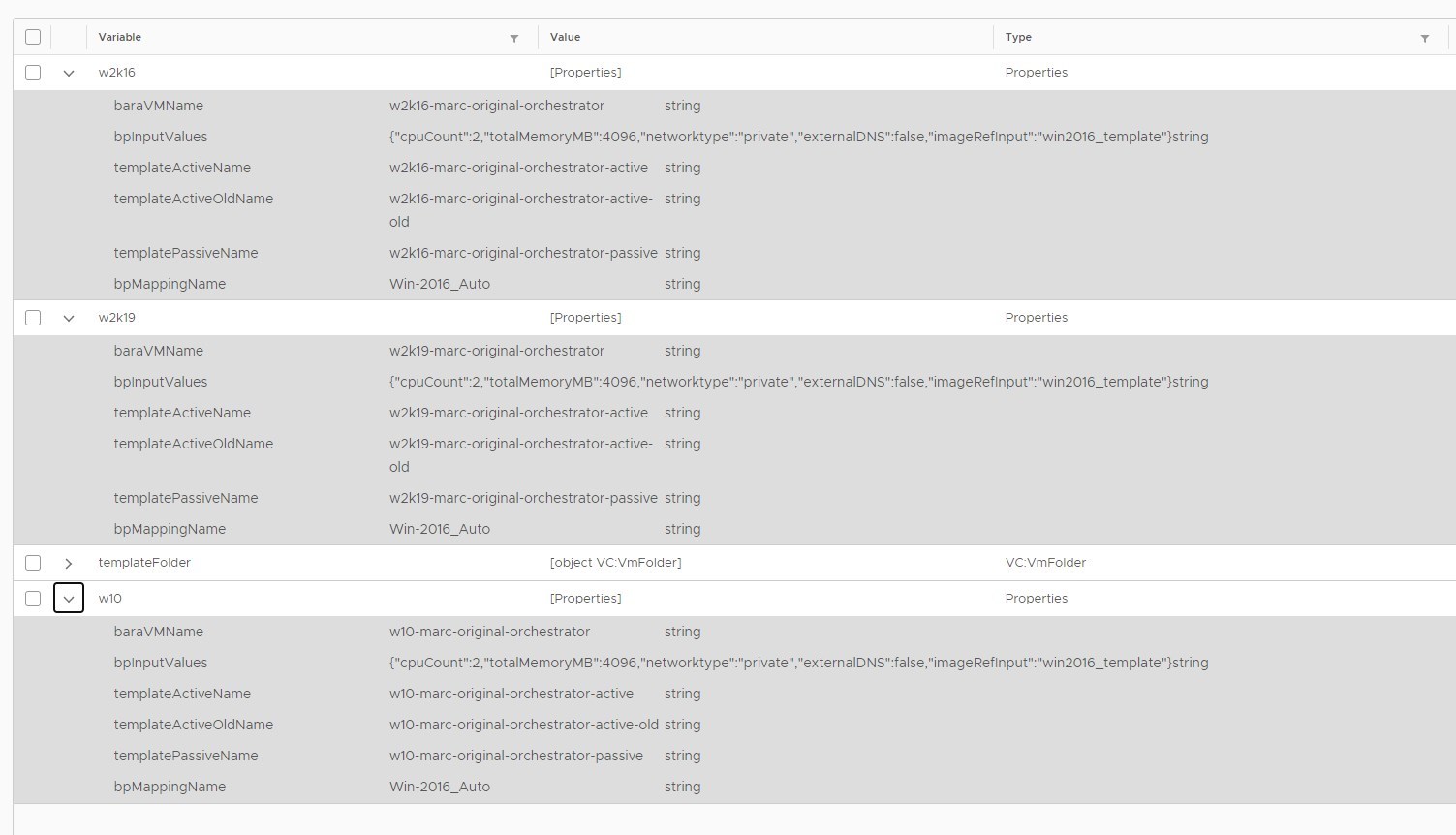
Having this configuration element in place we can use its keys and values wherever needed during the process. Having these separate from any code, it also provides us with an easy way to make everything portable between systems as you only have to change the values in one central place.
PS: For testing purposes I will use the same example blueprint and example image for every OS type. They will of course be distinctive values later.
1. Workflow: “Update VM Templates”
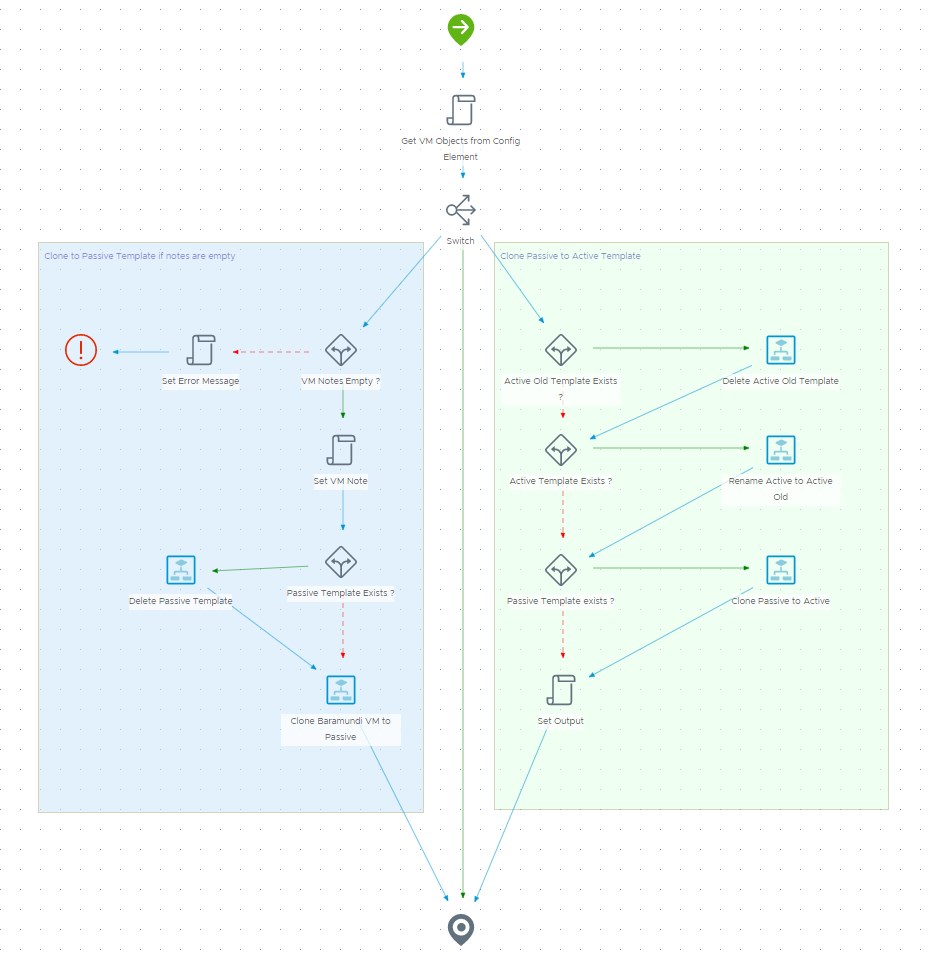
I decided to cover everything needed to do all the template switching in one workflow using an input argument to switch between what it actually does:
- Clone VM to passive template
- Clone passive to active template
This workflow will get triggered two times during the Codestream pipeline since there is a user interaction before the active template gets overwritten. For the most part it will make use of the built-in workflows you can find in vRO’s library in the “vCenter"folder. They serve the purpose as they are, no need to re-invent the wheel here. Of course you must have a vCenter object in your inventory to execute against.
A few things to explain:
- I made use of the VM notes field in vCenter as this an indicator for the VM being a fresh deployment from Ansible or Baramundi (There is a another team handling this, so we agreed on that). I will only continue if it’s empty. If not, this value is coming from a previous execution of the workflow. Like this we will prevent our old template from being overwritten by multiple pipeline executions triggered by the user.
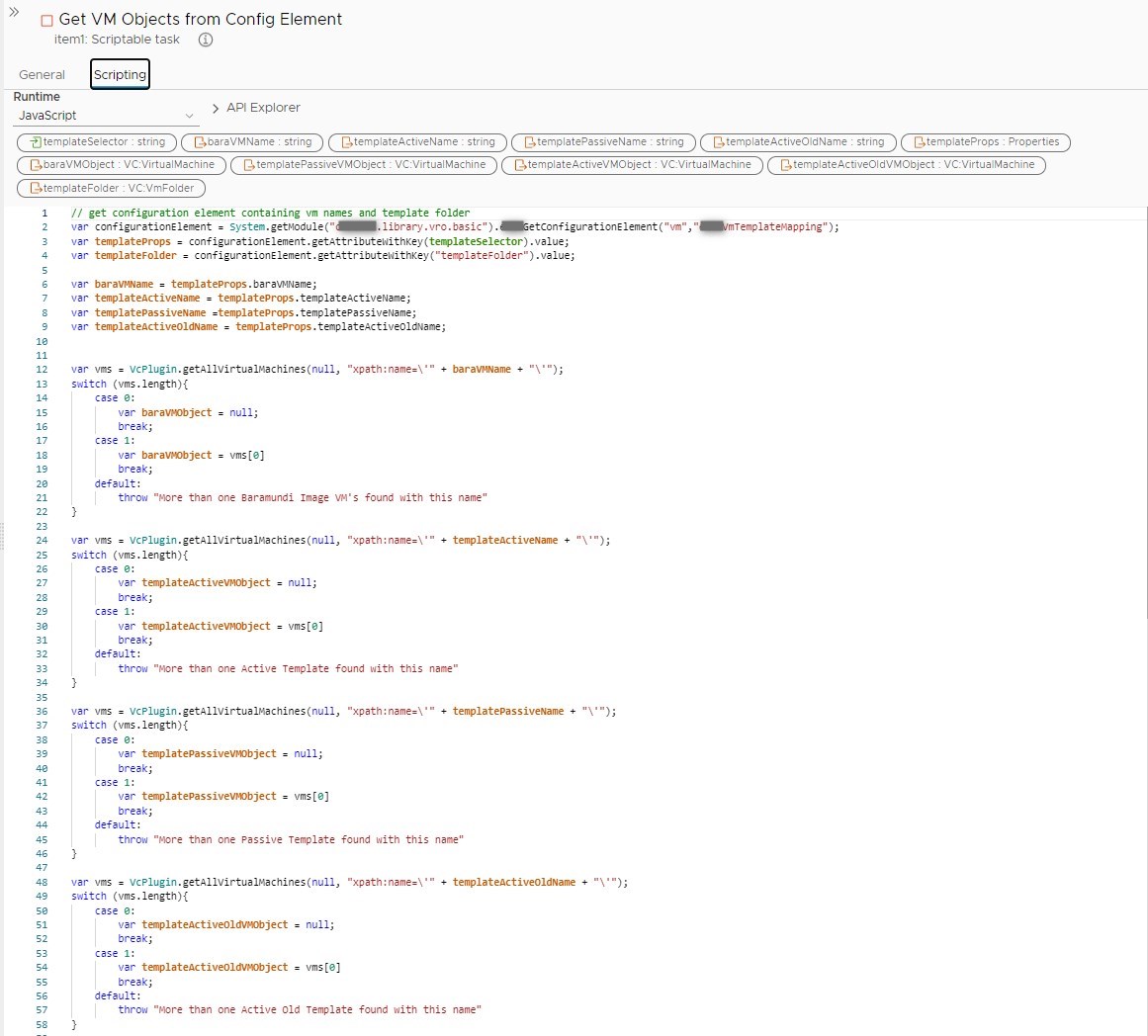
- As a first step I will get all values from the configuration element created previously for the selected OS (input value). I also search the corresponding VC:VirtualMachine object in vCenter. The search string should return exactly what I’m looking for, but I still handle this situation as a safety net if not. I included this script as a picture so you can have a look.
- If new VM templates come into play there might be the possibility that some objects do not exist, so I always check for this before executing the vCenter workflows.
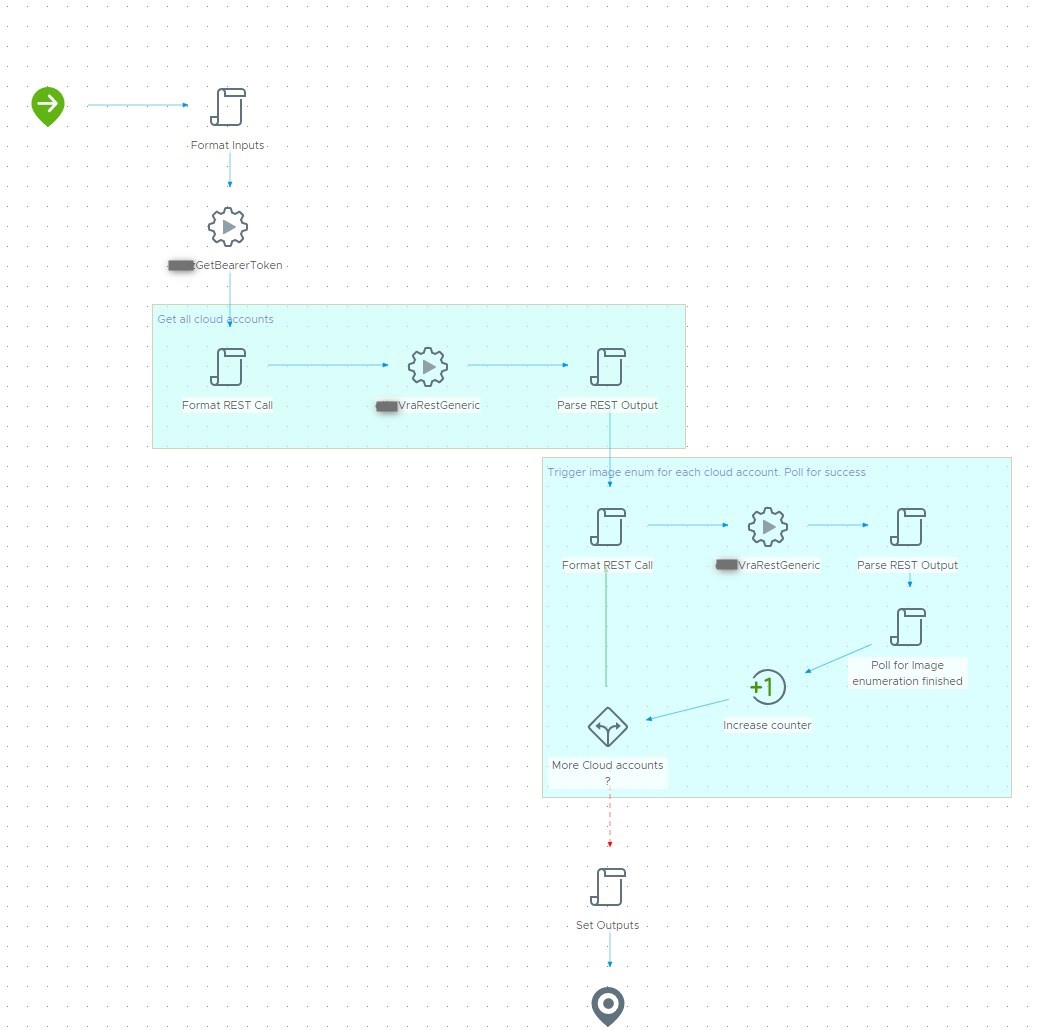
2. Workflow: “Trigger Image Enumeration”
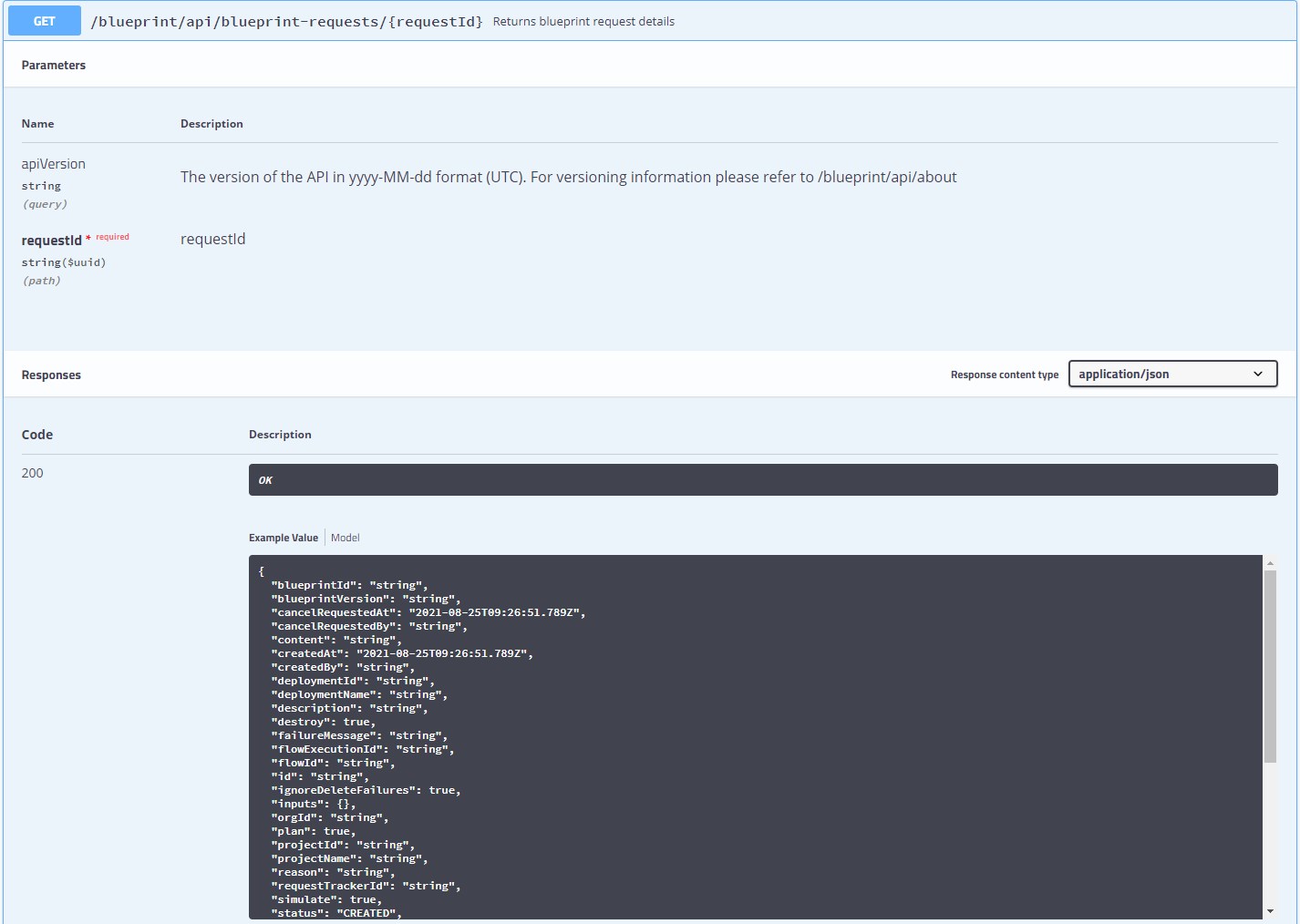
Next up we need a Workflow to make vRA aware of new images. In vRA terms this is called “Image enumeration” and the corresponding API call can be found in the swagger doc (https://{{vra-url}}/automation-ui/api-docs/):
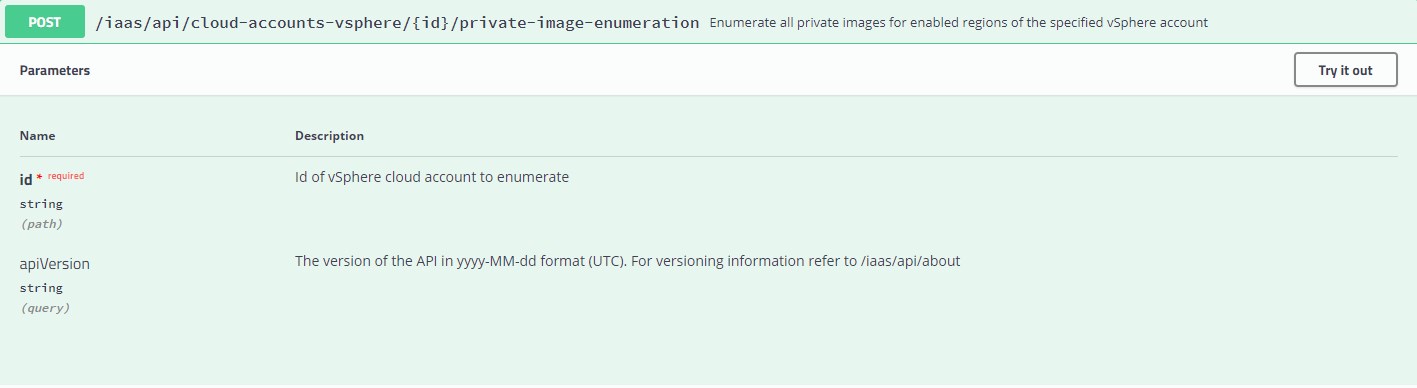
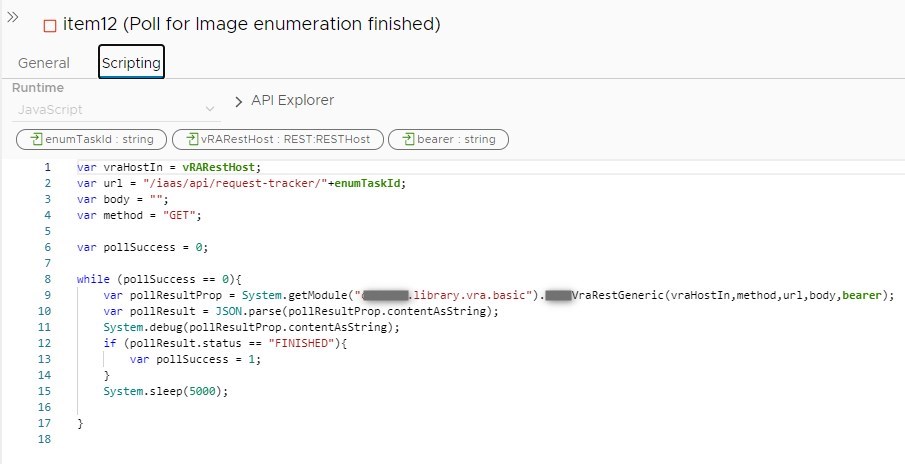
As you can see, we need to issue a POST request to the given URL including the cloud account ID. In my case I decided to get all cloud accounts beforehand and push those to an array. I will then loop over the array to trigger an enumeration for all available cloud accounts and poll for each completion as this could take a few seconds. I included a snippet of the poll task so you can see how this can be done by a reqest-tracker API call.
As an indicator for a successful enumeration we will have an output value that we can bind later in Codestream.
3. Workflow: “Request Blueprint”
This is the workflow we are going to use to deploy our passive template during the codestream pipeline. Looking at the swagger doc the basic API call looks like this:
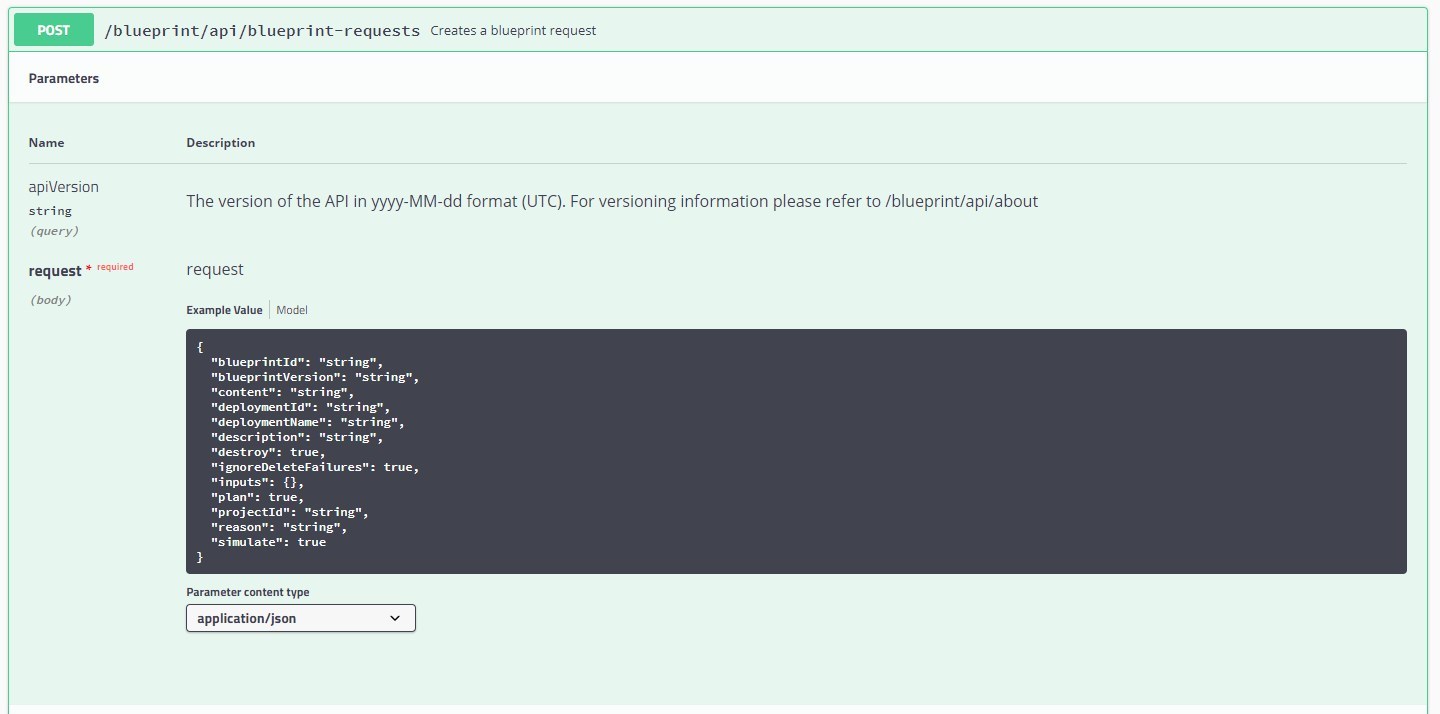
As you can see this calls needs a few values in the request body that we have to provide. You probably already discovered in the last workflow that I choose to code the individual API calls as generic actions for re-usability. The actions basicly take care of piecing together the correct URL and finally call another action I have written that executes the call against the vRA REST host. Here’s an example of a blueprint request action:
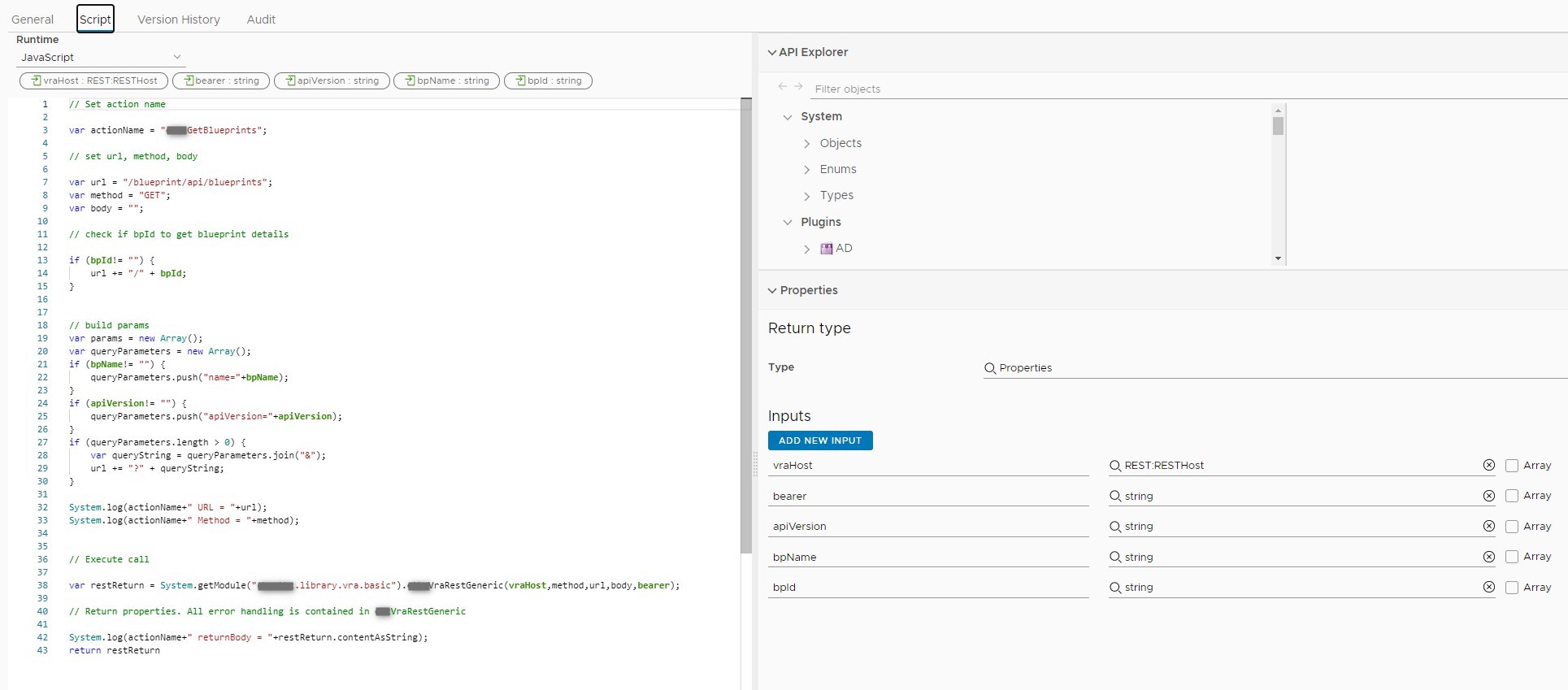
We are now going to use this in the workflow that will get called by the Codestream pipeline. Remember the configuration element we built ? When executing this workflow during the pipeline run we are actually going to make use of this by getting a few input values from there :
- bpRequestBodyInput
- bpName
We can either specify the projectName or the projectId as Input for this workflow. In this case it’s projectId which we will get from the Service Broker form (I will cover that later).
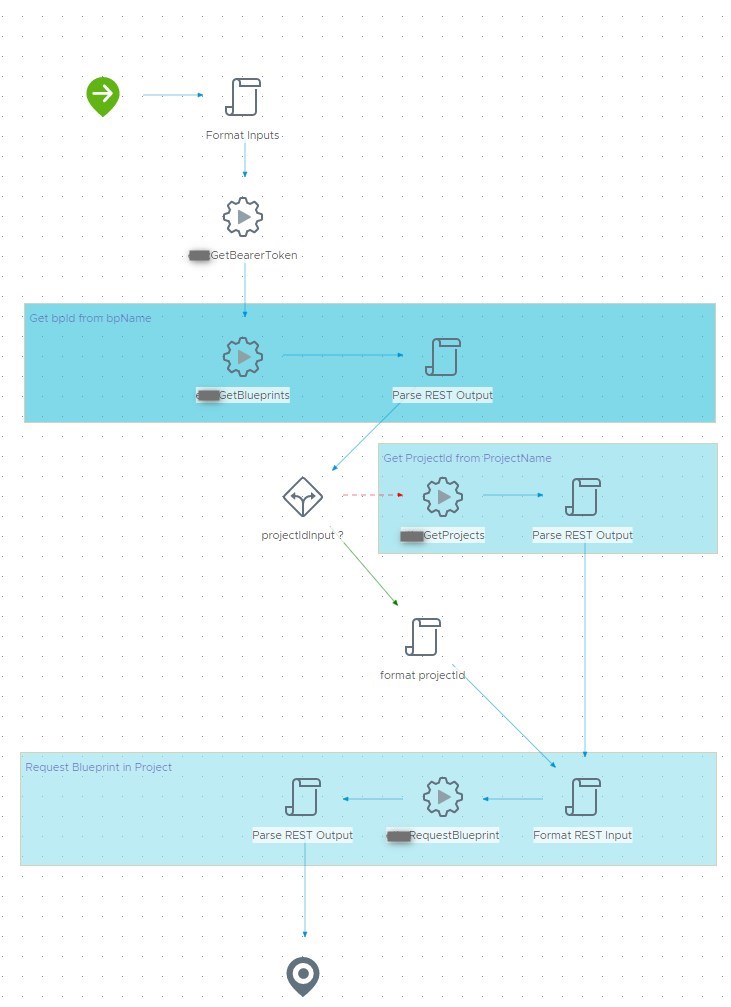
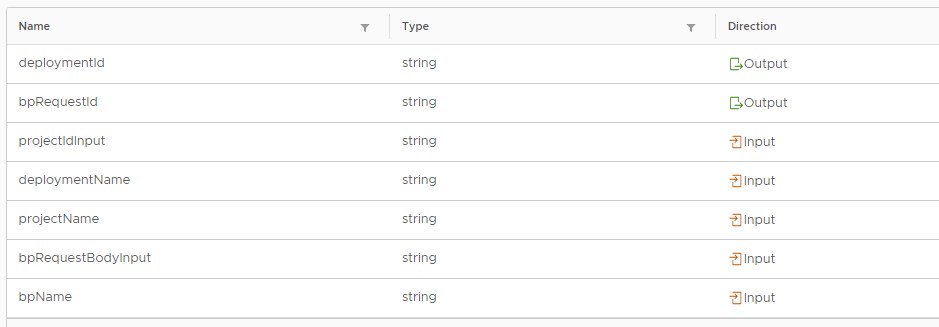
I choose to output the deploymentId and bpRequestId. We can get both values from the return body after executing the request:
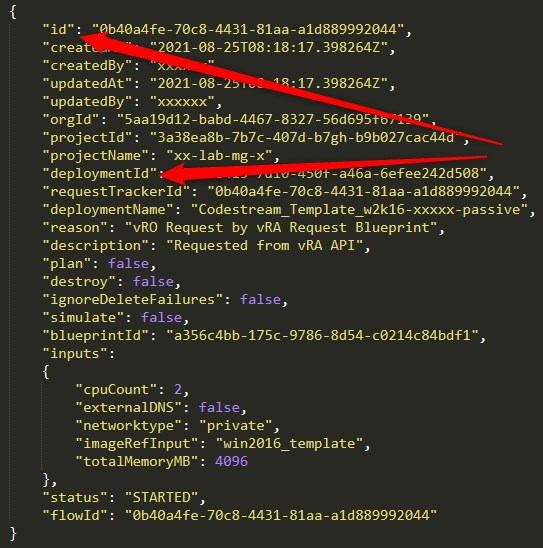
We are going to use these later in the pipeline to be able to poll for blueprint request completion and to delete the deployment.
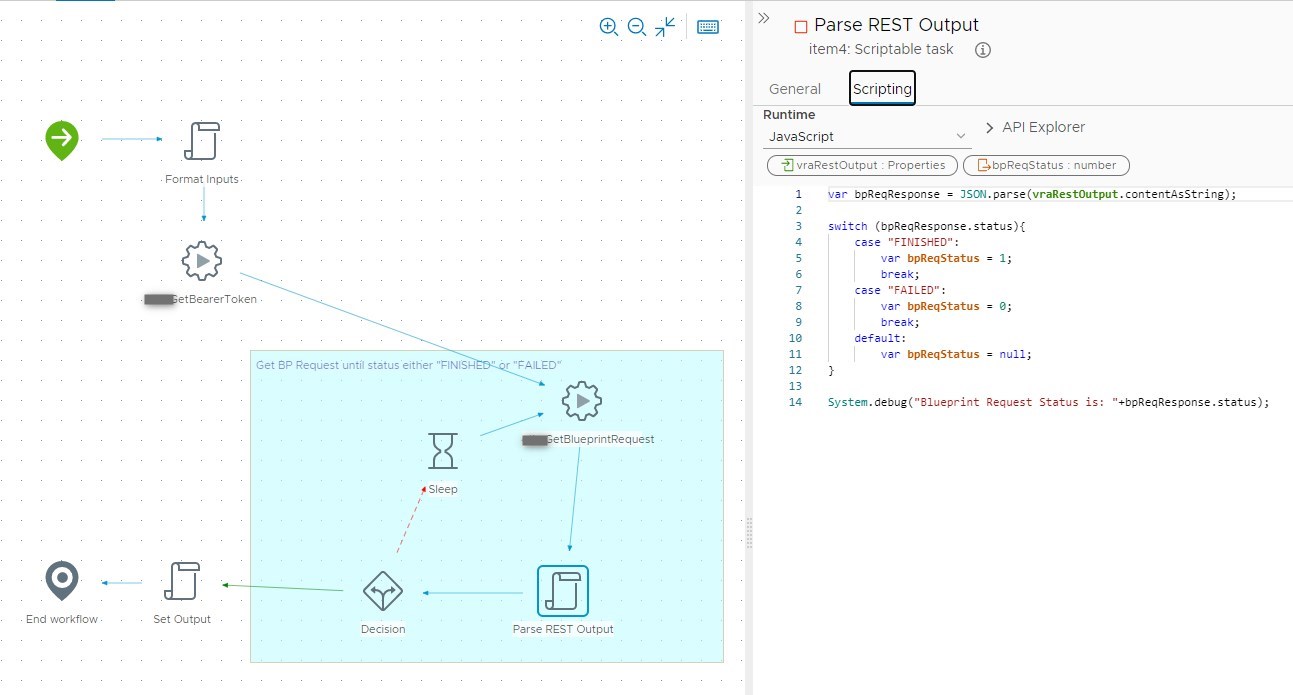
4. Workflow: “Poll Blueprint Request”
When we deploy the passive template during the Codestream pipline run we want to make sure that the request has actually finished successfully. If you look at above JSON again you see that there is also a “status” key in the body. We might poll for that in a workflow and return a status code for the pipeline to handle. Also in this case I wrote a separate action for this executing the call according to the swagger doc.
We can use this workflow twice in the pipeline, once for polling the blueprint request and later for polling deployment deletion.
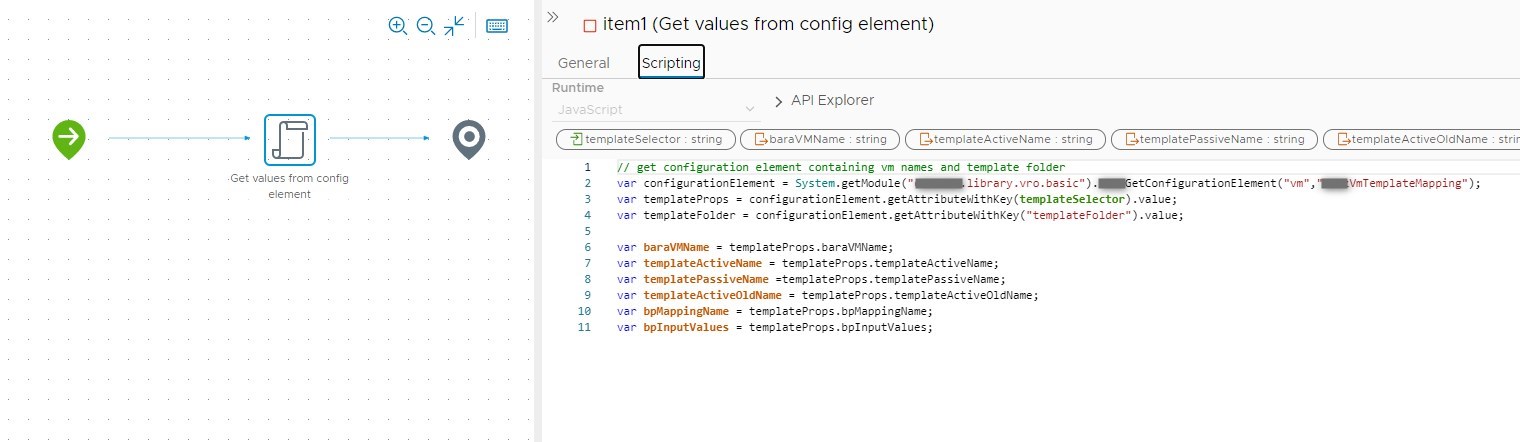
5. Workflow: “Get template mapping”
As codestream can only execute vRealize Orchestrator workflows and no actions we need a little workflow to get some values from our configuration element as we need these during the pipeline run. The values will be written to the output of the workflow:
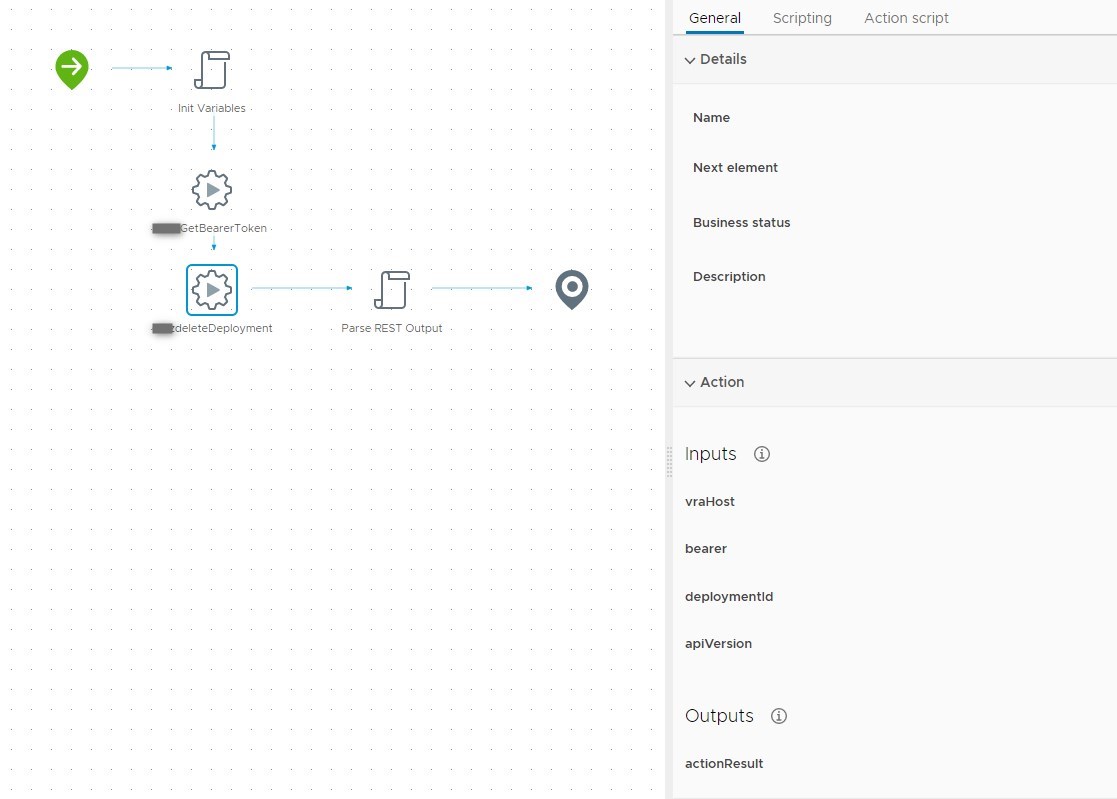
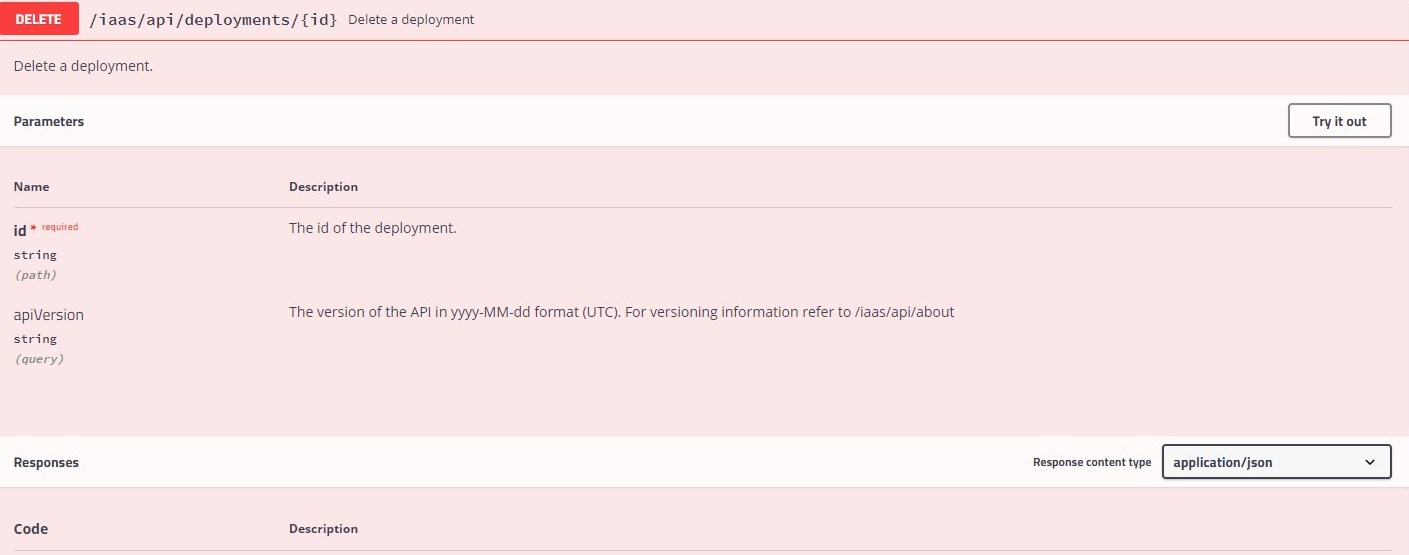
6. Workflow: “Delete Deployment”
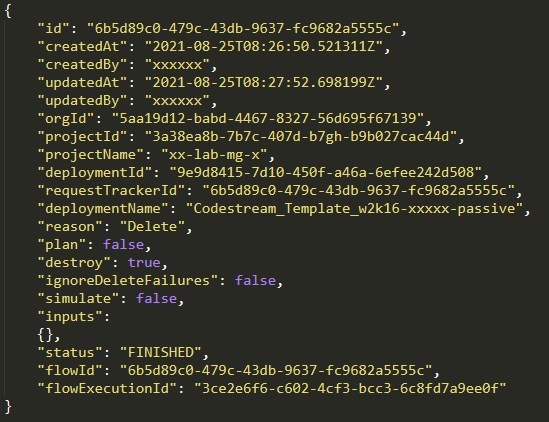
Which leaves us with our final task: Deleting a deployment. In this case it’s the deployment resulting from the passive blueprint we requested earlier on. That’s why we wrote the deploymentId to the output, we need it here.
As always, we check the swagger doc and write an action according to this for later use. The resulting workflow is quite simple. In this case the return body of the DELETE call will give us an ID that we can poll with our polling workflow since this is actually a day-2 blueprint action request with the key “destroy” being set to true.
Conclusion
In the first part of this post we focused on building our vRealize Orchestrator toolset. In the next part we proceed to the fun part: Putting together the vRealize Codestream pipeline and finally trigger it via vRealize Automation Service Broker.
I hope you enjoyed this post. If you have any questions or suggestions you can use the comment section. Feel free to share this with the social icons below if you think this could be interesting for your contacts.